A Wccftech friss cikke az NVIDIA saját technikai blogjára hivatkozva arról ír, hogy a GB300 NVL72 az új AA-AgentPerf benchmarkban akár 20-szor több agentikus kódolási munkát képes kiszolgálni megawattonként, mint a Hopper-generációs H200. A fontos apróbetűs rész: ez nem általános “20x gyorsabb GPU” állítás, hanem egy nagyon konkrét, párhuzamos AI-agent munkafolyamatokra kitalált mérés.
Mit mér az AA-AgentPerf?
Az NVIDIA technikai blogja szerint az AA-AgentPerf nem egy klasszikus token/s benchmark. A cél az, hogy megmutassa, egy inference rendszer hány párhuzamos AI-agentet tud futtatni úgy, hogy közben tartja az előre meghatározott szolgáltatási szintet. Vagyis nem csak az számít, hogy egy modell egy kérdésre milyen gyorsan válaszol, hanem az is, hogy sok hosszú, tool használós, kódolós agent-session egyszerre mennyire tartható életben.
Ez azért fontos, mert az agentikus AI másképp terheli a hardvert, mint egy sima chatbot. Egy kódoló agent nem egyetlen promptot kap és kész. Fájlokat olvas, eszközöket hív, több körben gondolkodik, változó hosszúságú kontextussal dolgozik, majd újabb LLM-hívásokat indít. Ezt a fajta terhelést a hagyományos, szép egyenes benchmarkok sokszor rosszul mutatják meg.
A 20x itt megawattonként értendő
Az NVIDIA által közölt eredmény szerint a GB300 NVL72 61,4 ezer párhuzamos agentet tud kiszolgálni megawattonként, míg a H200-nál ugyanez 2,6 ezer. Acceleratorra bontva a különbség szintén nagy: 57,5 concurrent agent GPU-nként a GB300 oldalán, szemben a H200 1,4-es értékével.
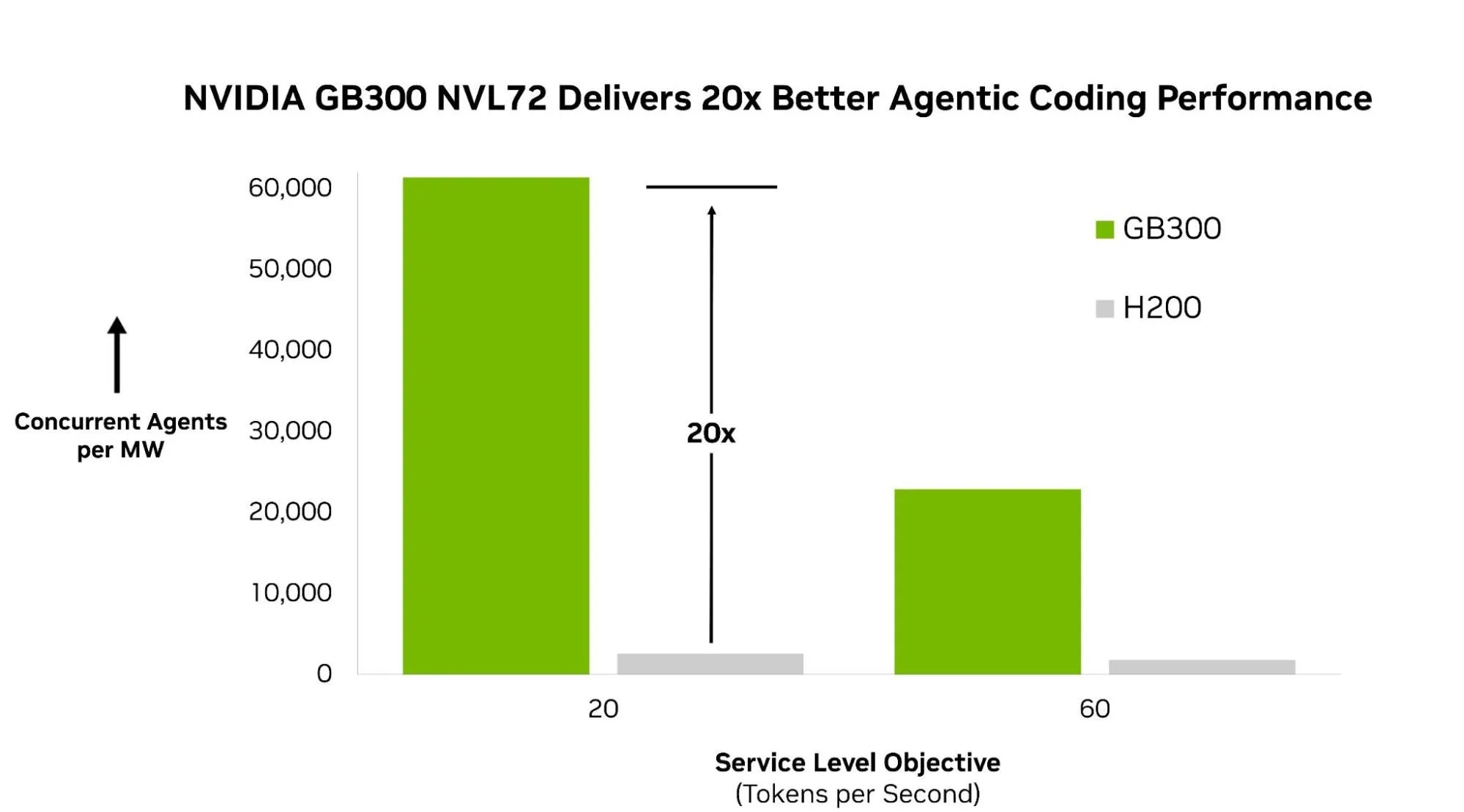
Ez látványos különbség, de nem ugyanazt jelenti, mint amikor egy videokártya játékban 20-szor több képkockát rajzol. Itt adatközponti kapacitásról van szó: adott teljesítménykeret mellett mennyi AI-agentet lehet párhuzamosan futtatni úgy, hogy a válaszidő és a tokenkibocsátás még elfogadható tartományban maradjon.
Miért pont az agentikus kódolás lett a mérce?
Azért, mert most ez az egyik legjobb stresszteszt az AI-infrastruktúrának. Egy kódoló agent hosszú kontextust használ, sok apró döntést hoz, tool callokat indít, és nem mindig ugyanazon az úton jut el a megoldásig. Emiatt nehezebb optimalizálni rá, mint egy előre kiszámítható, rövid chatválaszra.
Az NVIDIA szerint a GB300 NVL72 előnye nem csak a nyers tensor teljesítményből jön. A 72 GPU-s NVLink-domain, a nagyobb memória, a Blackwell Ultra architektúra és a szoftveres oldalon használt optimalizációk együtt számítanak. A cég külön említi a MoE-modellek hatékonyabb kiszolgálását, a KV cache és az ütemezés kérdését, illetve azt, hogy a rendszer sok párhuzamos agent-session alatt is magasan tudja tartani a GPU-k kihasználtságát.
Ez az NVIDIA válasza az AI-agent korszakra
A GB300 NVL72 hivatalos termékoldalán az NVIDIA már eleve az AI reasoning és az AI factory irányából pozicionálja a rendszert. A platform 72 Blackwell Ultra GPU-t és 36 Grace CPU-t fog össze egy rack-scale, folyadékhűtéses rendszerben. A cég szerint a GB300 NVL72 1,5-szer nagyobb sűrű FP4 Tensor Core teljesítményt és 2-szer magasabb attention teljesítményt kínál a sima Blackwell GPU-khoz képest, miközben az AI factory outputot Hopper-alapú rendszerekhez képest akár 50-szeresre pozicionálja.
Ez a számháború persze erősen NVIDIA-keretezésű, ezért érdemes óvatosan olvasni. A lényeg nem az, hogy minden AI-feladat holnaptól ötvenszer gyorsabb lesz, hanem az, hogy az NVIDIA szerint a következő nagy adatközponti szűk keresztmetszet nem a “modell fut-e” kérdés, hanem az, hogy hány agent fut egyszerre, mennyi energiából, és mennyire stabil válaszidővel.
Rubin már a következő körre készül
A cikk végén az NVIDIA már a Vera Rubin platformot is előveszi. A vállalat szerint a Rubin generáció 50 PFLOPs NVFP4 számítási teljesítménnyel és a Vera CPU-val viheti tovább ezt az irányt, főleg ott, ahol az LLM-hívások mellett a tool callok, az adatmozgatás és az end-to-end agent workflow is beleszól a teljesítménybe.
Ez jól mutatja, merre fordul a szerveres AI-piac. Már nem elég azt mondani, hogy egy gyorsító sok FLOP-ot tud. Az AI-agenteknél a memória, az interconnect, az ütemezés, a CPU-oldali tool callok és az energiahatékonyság együtt döntenek. A GB300 most ebben a narratívában kapott egy nagyon erős NVIDIA-számot: 61,4 ezer párhuzamos agent megawattonként. Ha az AA-AgentPerf valóban szélesebb iparági mércévé válik, akkor ez a szám még sokáig vissza fog köszönni az AI-hardveres vitákban.