
A Liquid AI június 25-én kiadta eddigi legkisebb nyelvi modelljét. A vállalat hivatalos bemutatója szerint az LFM2.5-230M mindössze 230 millió paraméterből áll, és elsősorban helyben futó adatkinyerési, eszközhasználati és könnyű agentikus feladatokra készült. Telefonon vagy egy Raspberry Pi 5-ön is elfut, tehát nem adatközponti óriásmodell kicsinyített másáról van szó.
213 token másodpercenként egy Galaxy S25 Ultrán
A Liquid AI 4 bites kvantálással, 2000 tokenes bemeneti környezetben mérte a modellt. Egy Snapdragon 8 Elite lapkás Samsung Galaxy S25 Ultra készüléken 1158 token/másodperces előtöltési és 213 token/másodperces dekódolási sebességet kapott. A futás közben mért memóriaigény 375 MB volt.
Raspberry Pi 5-ön 523 token/másodperces előtöltést és 42 token/másodperces dekódolást mértek, 293 MB memóriahasználat mellett. Ezek gyártói eredmények, meghatározott kvantálással és beállításokkal; más programkönyvtár, hosszabb kontextus vagy eltérő hardver más számokat adhat.
Hibrid felépítés, 32 ezres kontextus
Az LFM2.5-230M tizennégy rétegből áll: nyolc kettős kapuzású LIV konvolúciós blokkot és hat csoportos lekérdezéses figyelmi, vagyis GQA-blokkot kombinál. A kontextusablak 32 768 token, a modell pedig tíz nyelvet támogat. Magyar nincs a felsorolt nyelvek között.
A modellt 19 billió tokenes tanítási kerettel készítették. A finomhangolás első szakaszában a 350 millió paraméteres LFM2.5-350M válaszaiból desztillálták, majd preferencia-optimalizálást és több területre kiterjedő megerősítéses tanulást kapott.
Egyes teszteken nagyobb modelleket is megelőz
Az utasításkövetést mérő IFEval teszten 71,71 pontot ért el. Ezzel a Liquid AI saját mérése szerint megelőzte a Gemma 3 1B IT 63,49-es és a Qwen3.5-0.8B 59,94-es eredményét. A CaseReportBench adatkinyerési teszten 22,51 pontot kapott, szemben a Qwen 13,83-as és a Gemma 2,28-as értékével.
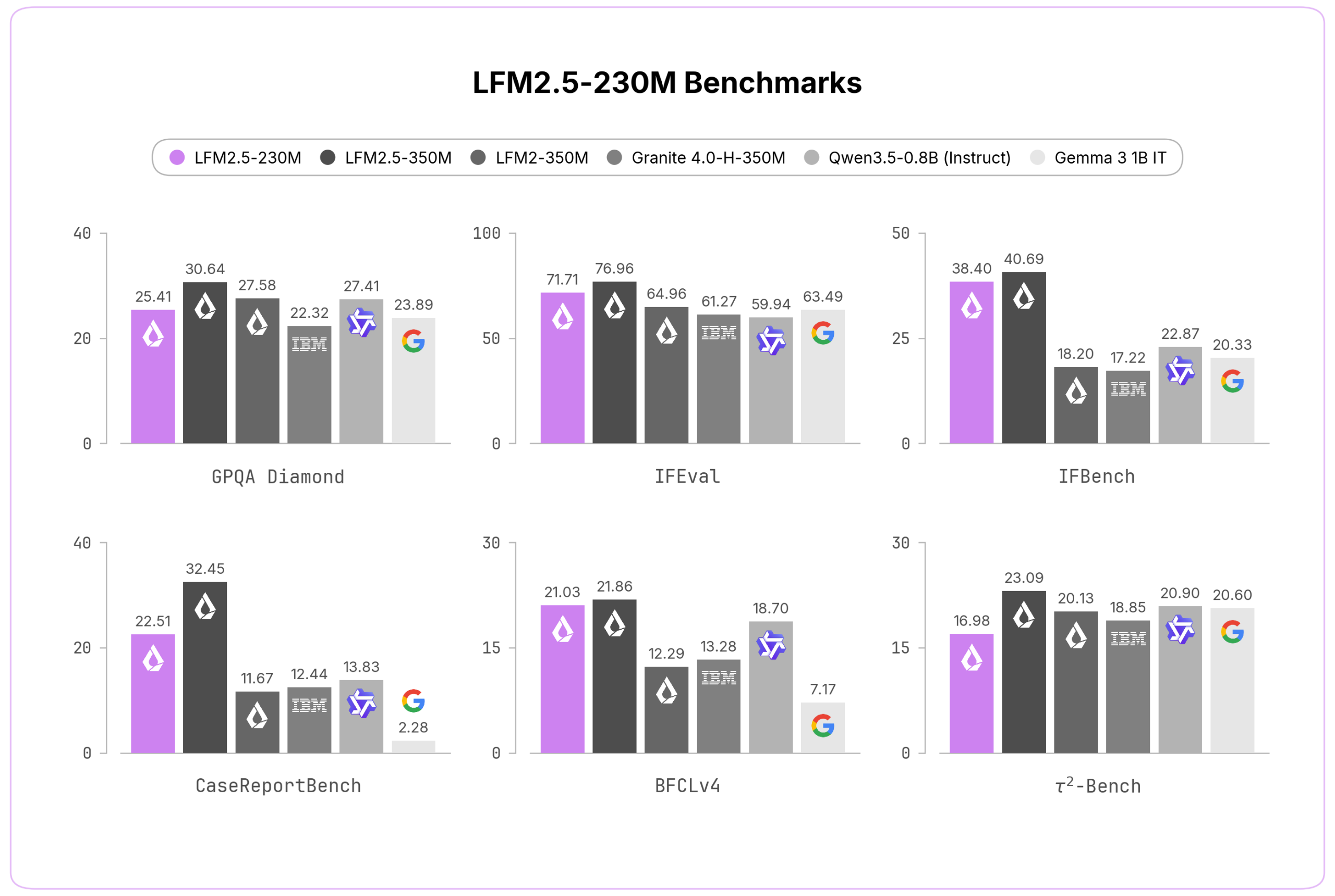
Ettől még nem lett általánosan jobb náluk. GPQA Diamond és MMLU-Pro alatt például a Qwen3.5-0.8B erősebb, és a nagyobb LFM2.5-350M is szinte minden mérésben előrébb végzett. A 230M-es modell előnye a méret, a sebesség és az, hogy szűk feladatokra könnyen helyben tartható.
Mire használható, és mire nem?
A Liquid AI adatkinyeréshez, strukturált válaszokhoz, eszközhíváshoz és kisebb, helyben futó agentikus folyamatokhoz ajánlja. A vállalat egy Unitree G1 humanoid roboton is kipróbálta: a Jetson Orin fedélzeti gépén természetes nyelvű utasításokat bontott előre betanított mozgáskészségekre.
Összetett matematikára, komoly kódgenerálásra és kreatív szövegírásra maga a fejlesztő sem ajánlja. A modell Transformers, llama.cpp, MLX, vLLM, SGLang és ONNX formában érhető el, így a lényeg itt nem egy újabb chatbot, hanem egy kicsi, célfeladatra szabható helyi komponens.


