Az Alibaba új Qwen AI-modellje egyre komolyabb figyelmet kap az AI-iparban. A legfrissebb Code Arena rangsor szerint a vállalat egyik új modellje már több OpenAI- és Google-modellt is megelőzött programozási feladatokban. A történetről elsőként a South China Morning Post számolt be.
A jelentés szerint az Alibaba jelenleg az egyetlen nem amerikai vállalat, amely bekerült a Code Arena toplistájának élmezőnyébe. A fókuszban a Qwen modellcsalád legújabb verziói állnak, amelyek főként:
- kódgenerálásban,
- agentic workflow-kban,
- és hosszabb fejlesztési feladatokban teljesítenek erősen.
Az Alibaba az elmúlt egy évben rendkívül gyors tempóban fejlesztette a Qwen családot. A legújabb modellek között már külön:
- reasoning,
- coding,
- multimodális,
- és agentic verziók is találhatók.
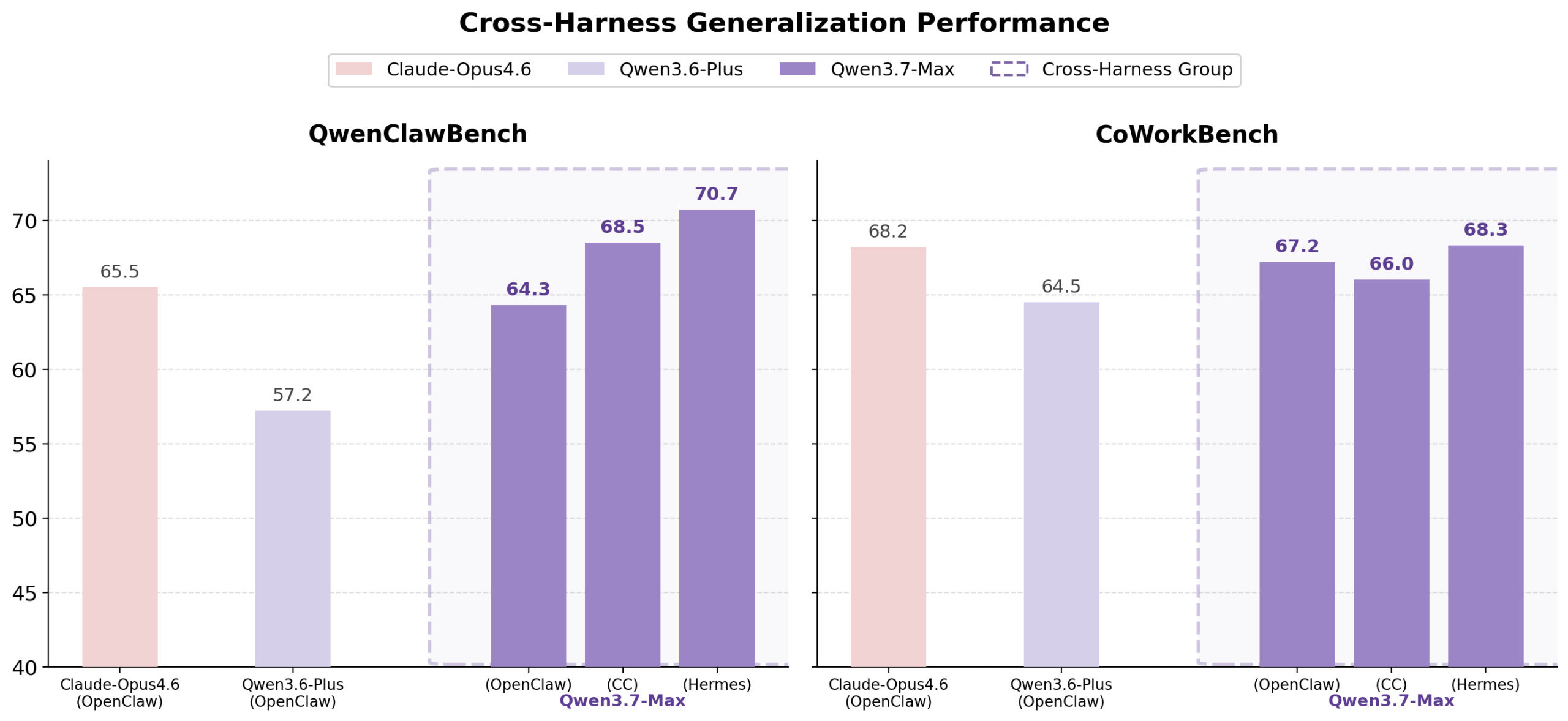
A vállalat állítása szerint a Qwen3.6-Max-Preview több kódolási benchmarkon is az élmezőnybe került, köztük:
- SWE-bench,
- Terminal-Bench,
- SkillsBench,
- és SciCode teszteken.
Az Alibaba emellett azt is hangsúlyozza, hogy a modellek egyre jobban optimalizáltak hosszabb autonóm munkafolyamatokra és tool-using feladatokra.
Az AI-verseny már nem csak az OpenAI-ról szól
Az elmúlt két évben az AI-piacot főként az OpenAI, a Google és az Anthropic dominálta.
Most viszont egyre több kínai vállalat kezd felzárkózni:
- az Alibaba Qwennel,
- a DeepSeek saját reasoning modelljeivel,
- a Moonshot AI Kimi-rendszereivel,
- valamint a Zhipu AI GLM-modelljeivel.
A kínai modellek különösen:
- ár/teljesítmény arányban,
- nyílt modellstratégiában,
- és agentic AI-funkciókban próbálnak agresszíven versenyezni.
Egyre fontosabbak a coding benchmarkok
A programozási benchmarkok ma már az AI-ipar egyik legfontosabb versenyterületévé váltak.
A modern modelleket nemcsak egyszerű kódkiegészítésre használják, hanem:
- teljes projektek generálására,
- hibakeresésre,
- workflow-automatizálásra,
- agentic fejlesztésre,
- és infrastruktúra-kezelésre is.
Az Alibaba szerint a Qwen-modellek egyik fő erőssége éppen az, hogy hosszabb, több lépéses fejlesztési folyamatokat is stabilabban kezelnek.
A benchmarkok mögött továbbra is sok a kérdőjel
Fontos ugyanakkor, hogy az AI-benchmarkok világát továbbra is sok kritika éri.
A vállalatok gyakran:
- eltérő tesztkörnyezetet használnak,
- különböző modellverziókat hasonlítanak össze,
- vagy saját benchmarkokat publikálnak.
Több elemző ezért óvatosan kezeli az Alibaba állításait is. Ettől függetlenül egyre világosabb, hogy a kínai AI-modellek már nem egyszerűen felzárkózni próbálnak — hanem bizonyos területeken ténylegesen versenyképessé váltak a nyugati rendszerekkel szemben.


