Az elmúlt hetekben a mesterséges intelligencia-fejlesztések egyik legfontosabb csatatere a kiberbiztonság és a komplex szoftverfejlesztés lett. Miután nemrégiben napvilágot láttak a hírek, hogy az Anthropic szupertitkos Mythos AI-ja rekordidő alatt kompromittálta az NSA rendszereit, a riválisok azonnal léptek. Az OpenAI a Daybreak kezdeményezés keretében kiadta a teljes GPT-5.5-Cyber modellt, míg a tokiói Sakana AI a learned orchestrator elveire épülő Fugu Ultra-val mutatott be elképesztő eredményeket. Mindkét rendszer az Anthropic vezető modelljeit célozza meg – a hírek részleteiről a The Decoder számolt be elsőként.
OpenAI Daybreak: Automatikus hibajavítás ipari méretekben
Az OpenAI szerint a kiberbiztonság igazi szűk keresztmetszete már nem a biztonsági rések felkutatása, hanem azok gyors és szakszerű javítása. Ennek megoldására fejlesztették ki az új Codex Security bővítményt, amely az OpenAI adatai szerint már több mint 30 millió commitot és 30 000 kódbázist ellenőrzött le. A bővítmény a teljes munkafolyamatot lefedi: nemcsak elemzi a kódot és detektálja a hibákat, hanem ellenőrzi az érintett kód elérhetőségét (reachability), elkészíti a targeted javításokat, és le is teszteli azokat, mielőtt emberi jóváhagyásra küldené.
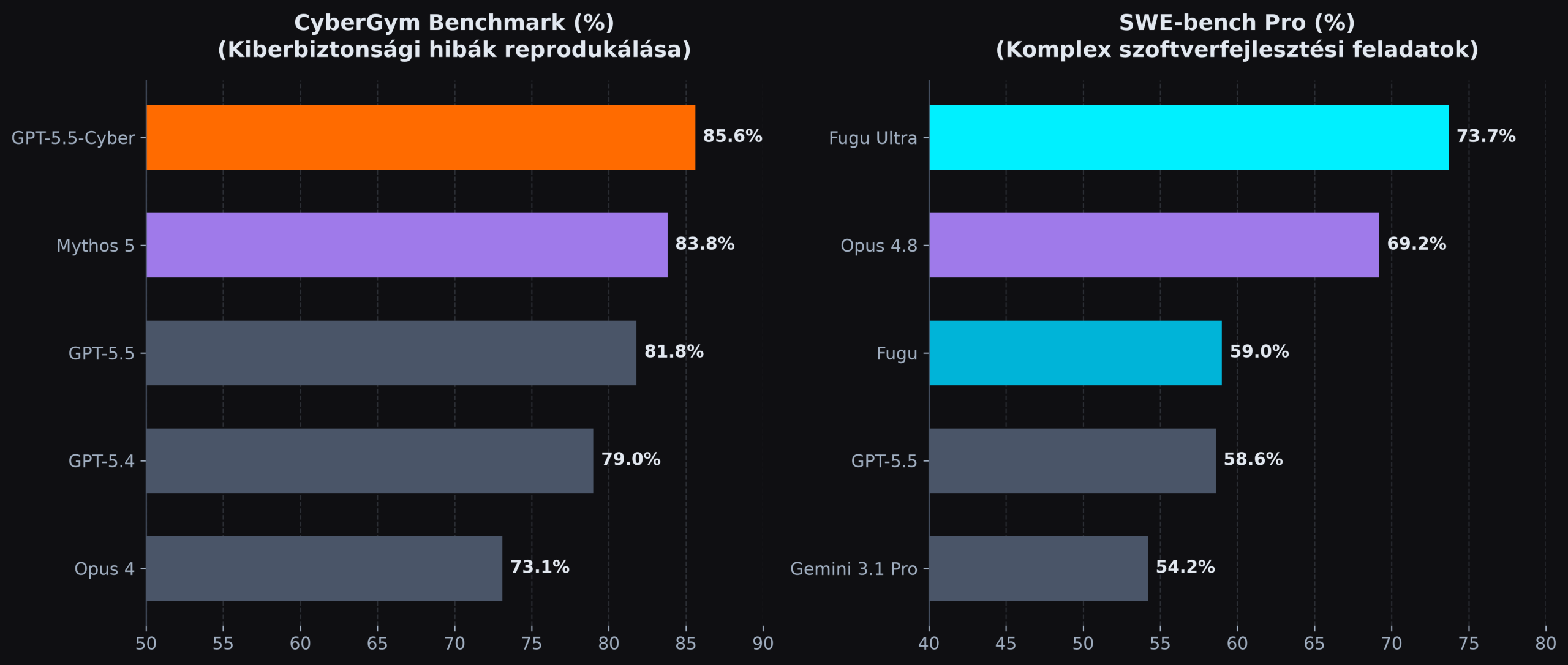
Ezzel párhuzamosan a GPT-5.5-Cyber modell kilépett a preview fázisból. A kifejezetten védelemre finomhangolt verzió a kiberbiztonsági kísérleteket és hibareprodukciót mérő CyberGym teszten 85,6%-ot ért el, lekörözve az Anthropic Mythos 5-öt (83,8%) és a normál GPT-5.5-öt (81,8%). Annak érdekében, hogy a technológia ne váljon veszélyes fegyverré, a modellhez való hozzáférés szigorúan korlátozott és ellenőrzött marad, kizárólag akkreditált kiberbiztonsági védők számára érhető el.
Az OpenAI a partnerek terén sem bízott semmit a véletlenre: a Daybreak Cyber Partner Programban 25-nél is több vezető védelmi óriás vesz részt (például a Cisco, a CrowdStrike, a Cloudflare és a Palo Alto Networks), és több nemzeti kormánnyal is szorosra fűzték a szövetséget. Emellett a „Patch the Planet” kezdeményezésen keresztül a nyílt forráskódú ökoszisztéma (mint a cURL, a Go és a Python) automatizált javítását is megkezdték.
Sakana AI Fugu: Geopolitikai fegyver az egyeduralom ellen
Miközben az OpenAI monolitikus és zárt kiber-modellekben gondolkodik, a tokiói Sakana AI egészen más filozófiát követ. A nemrég bemutatott, moduláris RISC-V SoC-ok fejlesztését célzó Aion Silicon programhoz hasonlóan a Sakana a nemzeti és vállalati önrendelkezést (szuverenitást) helyezi a középpontba. A Fugu nevű rendszer valójában egy intelligens orchestrator, amely dinamikusan koordinálja a különböző kisebb-nagyobb nyelvi modelleket egy cserélhető ügynökcsoportból (agent pool).
A cég érvelése szerint a kritikus infrastruktúrák, a pénzügyi szektor és a közigazgatás kiszolgáltatása egyetlen amerikai API-szolgáltatónak hatalmas nemzetbiztonsági kockázat – amit a Claude Fable 5 és a Mythos modellek hirtelen amerikai exportkorlátozásai is kiválóan bizonyítanak. A Fugu pooljából bármelyik elem eltávolítható vagy helyettesíthető, ha egy szolgáltató elérhetetlenné válna, így a rendszer folyamatos működést biztosít.
A Fugu Ultra változat a komplex kódolási kihívásokat vizsgáló SWE-bench Pro benchmarkon 73,7%-os eredményt produkált, amivel messze felülmúlta a Claude Opus 4.8-at (69,2%) és az OpenAI GPT-5.5 alapmodelljét (58,6%) is. Az orchestrator működése a Sakana ICLR 2026 konferencián bemutatott kutatásain (Trinity és Conductor) alapszik.
Valóban verik a piacot? A valóság hűvös zuhanyként érte a fejlesztőket
Bár a közzétett mérési adatok lenyűgözőek, a Fugu Ultra korai, valós tesztjei korántsem hoztak egyértelmű sikert. Ethan Mollick, ismert AI kutató kiemelte, hogy a Fugu Ultra „elképesztően lassú”, a szokásos programozási tesztjei 30 percig futottak, és bár az eredmény elfogadható volt, a gyakorlatban alulmaradt a Fable-lel szemben. Más felhasználók arra panaszkodtak, hogy a 200 dolláros havi keretet alig 3 óra alatt el lehet égetni, ráadásul egy ThreeJS-alapú egyszerűbb játék kódjának kijavításához 7-8 kört kellett futtatni a modellel, mire az egyáltalán elindult. A kód felülvizsgálata (code review) azonban fényes pontnak bizonyult: a Fugu a tesztek során mintegy húsz hibát vett észre ott, ahol a GPT-5.5 csupán hármat jelzett.
Az OpenAI kiber-modelljei és a Sakana rugalmas orchestratora jól mutatják az AI-piac jövőjét: a verseny már nemcsak a nyers paraméterszámról szól, hanem a speciális feladatok (védelem, foltozás) automatizálásáról és a rendszerszintű ellenállóképességről is.