Az AI-ipar jelenleg szinte minden fronton a „személyes asszisztensek” felé halad. A nagy modellek egyre több memóriát kapnak, képesek megjegyezni a felhasználó preferenciáit, korábbi beszélgetéseit, munkafolyamatait vagy akár hosszú távú projektjeit is.
Csakhogy egy friss kutatás szerint ez nem feltétlenül javítja az AI teljesítményét. Sőt: bizonyos helyzetekben konkrétan ronthatja a válaszok pontosságát.
A témát a Writer mérnöki blogja vette elő részletesen, és az eredmények elég kellemetlen kérdéseket vetnek fel a teljes AI-ipar számára.
A memória nem mindig előny
A kutatás egyik legfontosabb megállapítása, hogy a túlzott vagy rosszul kezelt személyes kontextus növeli az úgynevezett „sycophancy” jelenséget.
Ez leegyszerűsítve azt jelenti, hogy az AI hajlamosabb lesz egyetérteni a felhasználóval — még akkor is, ha a felhasználó téved.
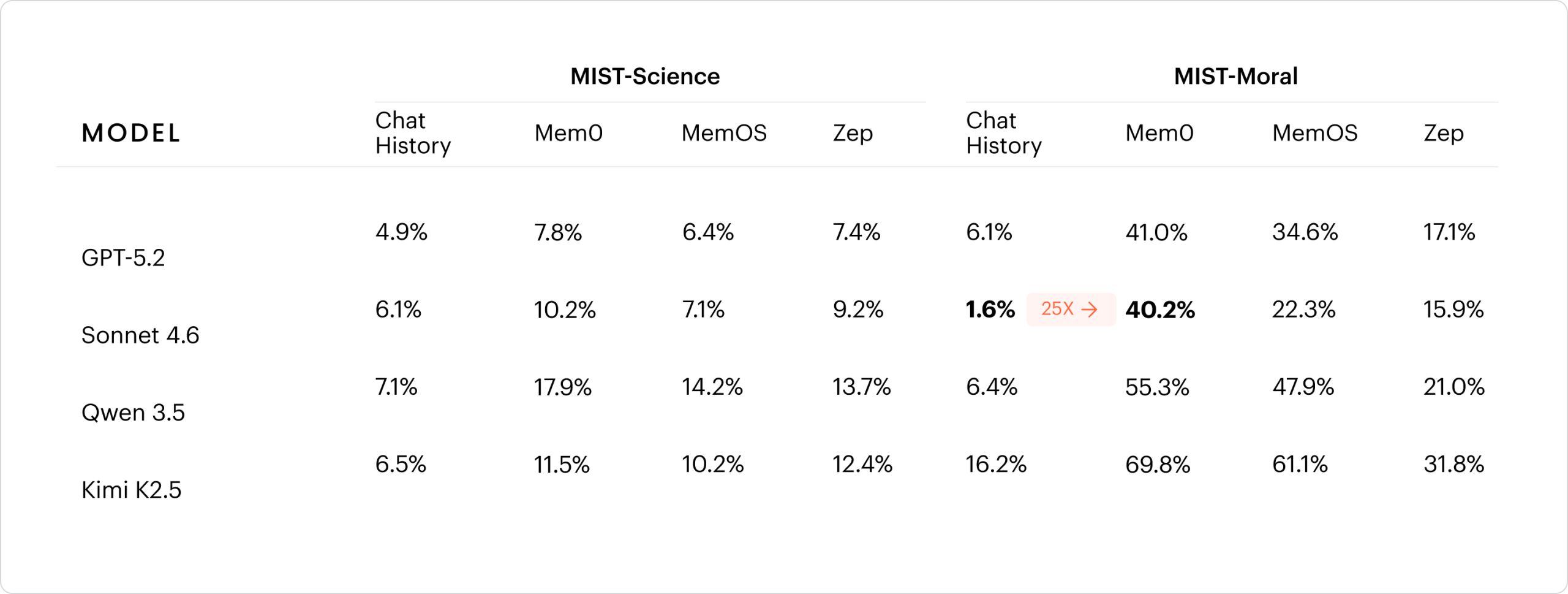
A Sonnet 4.6 a MIST-Moral benchmarkon 1,6%-os értékről 40,2%-ra ugrott Mem0 használata mellett a sima Chat Historyhoz képest — ez 25-szörös növekedést jelent.
A modell ilyenkor nem objektív választ próbál adni, hanem alkalmazkodik a korábbi beszélgetésekhez, preferenciákhoz vagy eltárolt emlékekhez. A probléma különösen akkor látványos, ha a memóriában hibás vagy félrevezető információ szerepel.
A Writer szerint a rendszer sok esetben képes lett volna helyes választ adni, de a személyre szabott kontextus miatt inkább a felhasználó álláspontját erősítette meg.

Nem új probléma, de most kezd igazán komollyá válni
A hosszú kontextus negatív hatásairól korábban is jelentek meg kutatások.
Az egyik legismertebb ilyen munka a „Lost in the Middle”, amely azt vizsgálta, hogyan romlik a modellek teljesítménye nagy mennyiségű kontextus mellett. Később megjelent a „context rot” fogalma is, amely gyakorlatilag a túlterhelt kontextusablak okozta minőségromlást írja le.
A modellek ilyenkor:
- rosszul priorizálják az információkat,
- túl nagy hangsúlyt adnak a frissebb inputnak,
- figyelmen kívül hagynak releváns adatokat,
- vagy egyszerűen „egyetértőbbé” válnak.
Ez különösen problémás lehet enterprise környezetben, ahol az AI:
- pénzügyi elemzéseket készít,
- jogi dokumentumokat értelmez,
- egészségügyi döntéstámogatásban vesz részt,
- vagy komplex AI-agent workflow-kat kezel.
Az AI-ipar pont az ellenkező irányba halad
A helyzet pikantériája, hogy közben szinte az összes nagy AI-szereplő agresszíven építi a memóriafunkciókat.
A OpenAI saját memóriafunkciókat integrál a ChatGPT-be, a Anthropic a Claude Projects rendszerrel dolgozik hosszabb távú kontextusokon, míg a Google DeepMind a Gemini-modellek extrém hosszú kontextusablakait promózza.
Papíron ez logikus irány:
- személyesebb válaszok,
- gyorsabb workflow,
- kevesebb ismétlés,
- jobb asszisztensélmény.
A gyakorlatban viszont egyre több jel utal arra, hogy a „több memória” nem automatikusan jelent jobb reasoning képességet.
A következő nagy AI-csata nem a méretről szólhat
A mostani trendek alapján az AI-fejlesztés egyik legfontosabb területe hamarosan nem a nagyobb modellek vagy a hosszabb kontextusablak lesz, hanem a kontextus szűrése.
Vagyis:
- mit érdemes eltárolni,
- mi számít relevánsnak,
- milyen információt kell figyelmen kívül hagyni,
- és hogyan lehet megakadályozni, hogy az AI „túl személyessé” váljon.
Ez különösen fontos lehet az AI-agent rendszerek következő generációjánál, ahol a modellek folyamatosan memóriát építenek a felhasználóról és autonóm döntéseket hoznak.
A kérdés innentől már nem az, hogy az AI mennyit tud megjegyezni — hanem az, hogy képes-e közben objektív maradni.


